
How to scale RL to 10^26 FLOPs
A roadmap for RL-ing LLMs on the entire Internet

TLDR: Reinforcement learning (RL) is the next training technique for building frontier-level AI models. To make it better, we need to train on more data. The current approach of scaling many environments simultaneously is messy and complicated. Instead, I propose we find a way to do next-token prediction on the Web using RL. This way, we learn to reason from general web data, instead of just math and code.
I’ve spent a good part of the past year in denial.
I was in denial because when OpenAI released o1, and explained their paradigm of test-time compute, I thought it was a good idea but mostly a way to get better performance out of models of fixed size. After all, letting models ‘think for longer’ by generating more tokens lets them do more internal computation.

So I wasn’t that surprised that these new models, termed reasoning models, gave better answers. And I especially wasn’t surprised when I found out these answers mostly came on problems that inherently require lots of computation, like difficult math and engineering test questions.
Don’t get me wrong: I always thought reasoning models were interesting. It’s cool to me that they generate “thinking traces” before giving answers (although the thinking traces might not be very reliable). And it’s amazing that the models were trained with reinforcement learning, a foundational technique in machine learning that was generally understood to be difficult to use effectively for real problems.
But I still thought of myself as a scale maximalist: all that really mattered, I thought, was training bigger models on more data. Anything else (read: reasoning models) appeared to be a coping mechanism, just a way to get by while we wait for the hardware needed to train bigger models.
I’ve spent the past few months working on RL research at Meta. It took a bit of time but I’ve come full-circle: something far more nuanced is happening with reasoning models. RL isn’t just a way to give models more compute. RL training really is teaching models something different, a way to use compute to generate better answers given finite model capacity. Through RL, models are clearly learning something that they’re not getting from pretraining.
Two waves of AI scaling
The AI research-into-production cycle moves through a few distinct phases. First, we as a community identify a new learning paradigm. Second, we find the correct datasets for training and design evaluations to know when our models are getting better, and by how much. And third, we scale it to all hell.
This cycle has happened already, exactly once. Pretraining. It started with the innocuous observation that models can learn quite a lot when trained on internet text data using next-token prediction. We realized that this gives intelligence improvements in just about every domain. And then we scaled.

And to be clear, pretraining research is ongoing. We’re still figuring out how to scale our models via bigger datacenters and better hardware and more efficient algorithms. And we’re gathering more and better data every year. But the upper bound of pretraining performance is really clear. To build better models, we need to give them more parameters and train them on bigger datasets. This is what the AI labs have been working on for three years or so now.
But as the dust settles on the pretraining frenzy, reasoning models are showing us a new way to scale. We’ve found a way to make models better that’s independent of the number of training tokens or model size.
The murky path to RL scaling starts with data
We’ve identified a new paradigm: learning to reason. But reasoning models are in their GPT-3 era: they’re trained on small datasets to do a narrow selection of tasks. We have a brittle proof-of-concept in the reasoning models of 2025. These models have achieved state-of-the-art scores on a small number of tasks, mostly expert-level math and coding questions.
In the case of pretraining, the path to progress was very clear. Models can learn via next-token prediction on just about any data, so we could simply scrape the entire Web and feed it to the models. And once we’d done that it became clear that our models were too small and we needed to make them much, much bigger.
But RL training is different. Let’s briefly remind ourselves how RL works:
Models like o1 are trained with verifiable rewards, meaning that after thinking and generating answers, we teach models by encouraging them to think more of the thoughts that led to correct answers, and less of the thoughts that led to incorrect answers. This is how RL algorithms like PPO (what o1 probably uses) and GRPO (the algorithm behind DeepSeek R1) work. They don’t teach, they incentivize.
So clearly we can only train RL models on tasks where we can score answers based on correctness. This is the idea behind verifiability, an RL buzzword used to describe tasks with a well-defined automatic scoring function. (The o1-style RL training paradigm is usually called RLVR, reinforcement learning with verifiable rewards, as to be distinguished from RLHF, or reinforcement learning from human feedback.)
Unfortunately, most things aren’t automatically verifiable. There aren’t perfect computer programs that can tell you whether an essay is good, for example, or an explanation.
In fact, things that we know how to automatically verify tend to be in the scientific domain. For example, OpenThoughts, a recently-released dataset of training data for reasoning models, contains four categories, Code, Math, Science, and ‘Puzzle’:

Ok, so we can see that there are at least four domains that contain verifiable problems that we can train on. But there are many open problems here. Are those all the verifiable things that exist? Are they equally valuable? During training should we randomly alternate between them or train separate models and then average?
In fact, in typical RL setups, we don’t even understand the marginal value of a single training example. One recent paper, Reinforcement Learning for Reasoning in Large Language Models with One Training Example, demonstrated that training on just a single example with thousands of different attempts of reasoning can actually produce a very good model:
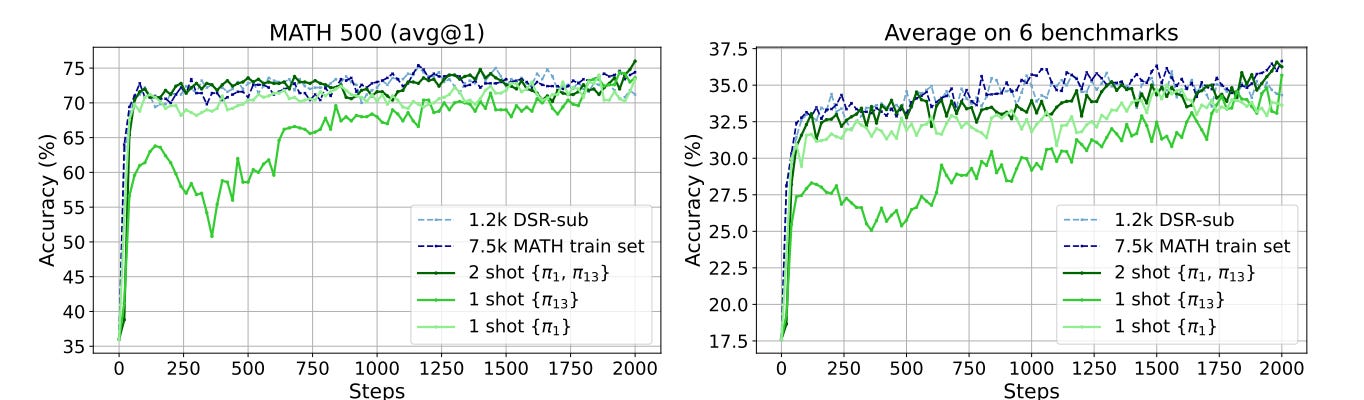
It’s also interesting to note the x-axis in the above graph: training only runs for 2000 steps. And that’s typical. Right now, these models are typically only trained for a few hundred or at most a few thousand steps. In the pretraining era, we often trained models on trillions of tokens, which meant millions of training steps.
This is mostly a compute issue: each step of RL requires sampling reasoning tokens, which is expensive and just difficult from a software perspective. The infrastructure to do this sort of thing is challenging and requires a lot of new engineering, since we aren’t used to doing generation at all during training, let alone at each step.
Mark my words: before we know it we’ll be running millions of steps of RLVR too.
RL compute scales unevenly
There are many practical engineering problems that need to be solved to scale RL.
In the pretraining days, training was a very homogenous workload, a very real-time continuous process. Batch of text passes through the model, we compute losses and backpropagate once. Queue the next back of text. This was simple and straightforward to optimize.
When we do RL, training infrastructure has to get more complicated. Gradient steps happen much less frequently and (depending on our chosen hyperparameters) we spend a lot more time generating thinking tokens.
Luckily, we’ve spent the last year or two making LLM inference super fast, and we can take advantage of these improvements here. In particular there are two really good libraries for doing inference (SGLang and vLLM) that make this part ~10x faster than naive python inference code. That helps a lot.
Another systems problem arises when we actually compute verifiable rewards. In the case of math problems this is usually pretty easy. Most datasets have answers computed ahead of time, so we can simply check if the final answer is correct and score accordingly (In practice, formatting makes this process slightly more complicated.)
But in domains besides math, verification quickly becomes expensive. This is especially noticeable in the code domain, which is where a lot of AI labs are focusing their efforts right now.
Remember that each domain needs a domain-specific “verifier”, a system that provides rewards that guide LLMs to generate better outputs. In the case of code, this usually involves running some code and scoring based on the code’s output. Given an LLM-generated answer to a coding problem, we may need to run a bunch of unit tests and count the number of ones that pass to provide a reward.
There are a lot of people working on this right now. Doing better and faster verification, running it in parallel, scaling it properly. In some cases, the training bottleneck isn’t anything related to the model – it’s not inference or backpropagation that slows things down, but the time it takes to compile and execute model code.

Since a single B200 costs over $500K, any time training spends bottlenecked by CPU execution is a big waste of money.
One path to scaling RL is optimizing this kind of system: making verifiers faster and more reliable, optimizing the new generate-before-backprop training pipeline, and designing clever systems that let us scale RL across datacenters.
In addition to all these systems-level improvements, we’ll need to build lots of new environments to try and learn diverse skills via RL training. Oh, and no one really knows what the right skills are to learn via RL, or how to combine them. So we’ll have to try lots of different combinations and train many models. And we can try averaging them in different ways via some kind of model souping (also known as model merging). We’ll just run lots of evaluations to find which combination of environments and souping produces the best model. This sounds difficult, doesn’t it? And quite messy.
What if I told you there was another way?
What does it mean to be verifiable?
If we want to scale RL in verifiable settings, we should probably start by figuring out which things are verifiable in the first place. It’s my feeling that people have been throwing this word around a lot, but there’s no clear definition.
It all comes down to what we can train into the models. If we can check a model output and provide a score, that’s good enough.
Wait– but isn’t this how language modeling works already?
Pretraining for reasoning with next-token prediction
Before making my proposal, let me start with listing a few core tenets that I believe about the current state of AI:
The only data we’ve found that really “works” (i.e. helps us build more intelligent models) is web-scale pretraining data. Ilya Sutskever famously compared all the human text on the internet to a reserve of fossil fuel: it’s exceptionally useful, but finite.
Reasoning, at its core, is a way to get better performance out of smaller models. It’s not doing anything more magical. Crucially, we’re getting limited new signal from the verifier itself; RL with verification is just a way to elicit capabilities that already exist within models. (This is a common belief about RL.)
There is nothing special about math and code. These modalities happen to lie in a space that’s difficult to model with a reward model (so prior approaches didn’t work super well) but easy to verify. And we happen to care about them (automating coding seems especially valuable). But we should be able to learn to reason from any type of data.
And finally, we haven’t fully saturated models with Internet data. Today’s models don’t seem to have enough capacity to memorize the entire Internet. Additional pretraining on Web data should still give us a performance boost – and might be enough to learn to reason.
Next-token prediction is verifiable. This is perhaps the central argument I’m making. The current strategy of checking if a math problem has been answered correctly is spiritually no different than confirming whether a model has outputted the proper next tokens.
Putting all this together, I’m betting that the “right way” to scale RL is by unifying it with next-token prediction. We should teach models to reason by practicing reasoning at scale on the vast diversity of data available on the Web.
Learning to reason via next-token prediction.

This shows a comparison of the new paradigm demonstrated on a math problem. Normal next-token prediction is guessing which tokens come next. Typical RLVR allows the model to ‘think’ for a few tokens and then rewards it for outputting the right thing. Our idea of reasoning with next-token prediction (RNTP) would allow the model to think and then reward it based on the next-token prediction loss of the outputs in the <answer> tag. It’s a hybrid between traditional language model pretraining and the new reasoning model RL training.
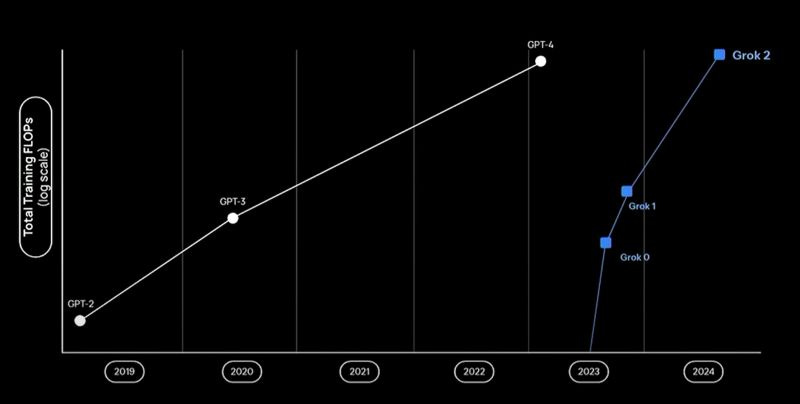
Grok 2 was trained on more FLOPs than GPT-4. Apparently Grok 3, which came out later, was trained on around 10^26 FLOPs, which would put it above the top of this graph. But that was all supervised learning. How do we scale RL to use this much compute?
What do we even need RL for?
Now that we’ve stripped things down to their base components, it might not be obvious what benefit we get from doing reinforcement learning, if any.
The answer lies in the <think> tokens. In the picture above, we generated everything between <thinks> directly from the model. There’s no supervision for this.
In other words, we’re trying to get the model to learn to reason without knowing what reasoning should look like. We just sample lots of things from the model and encourage it to do the things that get rewards. If there was ground-truth reasoning, we could use the typical supervised training techniques to train the model to output the proper reasoning chains.
But in the real world, there’s no ground-truth for reasoning, so we can’t do supervised learning. And in fact we want it this way – this is the magic of reinforcement learning. We’re hoping that the model will discover reasoning chains that are more useful than anything we could ever write ourselves.
Scaling reasoning via next-token prediction
If you’ve read this far, and you agree this idea makes sense, you might be thinking about how it could be tricky to implement.
And in fact, you’re right. This is where the research comes in. Almost all research that matters comes from figuring out how to implement and scale ideas that make sense from first principles.
For example: what exactly is the reward? Do we give the model a point for guessing a token correctly? Should we reward it more for multiple tokens in a row? Perhaps we use a string-similarity reward like BLEU score, as was common in machine translation in 2018. We could do some kind of self-evaluation, where a decent model can look at its own outputs and decide which ones should get rewards. Perhaps we filter tokens by entropy and use that to determine which to reason about. Or maybe we want to account for confidence in the reward, and give the model more points for being confidently correct.
Another question: how many times should you “reason” within a single text chunk? One approach is to insert reasoning tokens at a random position per-chunk. Or perhaps we allow models to reason multiple times throughout each chunk. But then we’d have to figure out whether how many times can learn from a given text chunk with different reasoning patterns before memorization starts to occur.
There are additional difficulties that arise when switching from math and code to general reasoning. One reason we like math and code is because they’re difficult for base models to do “from scratch” but often easy to learn via reasoning. This won’t be the case with general text: some tokens are already extremely low-entropy, and therefore easy to predict; other tokens are nearly impossible, and will never be guessed correctly with any amount of reasoning.

Andrej Karpathy recently noted that if you actually look at samples from a typical pretraining dataset, they’re quite ugly, and there is a lot of obvious noise. One benefit of scale is that it irons out many of these low-level idiosyncrasies: after a lot of training, much of this noise gets averaged away. It’s possible that this would happen with my proposed RL training scheme. If we train for long enough, on enough tokens, we might not even care what the exact reward or reasoning schema looks like.
But wait, didn’t somebody try this already?
Those among us who diligently troll ArXiv for the latest nuggets of progress might recognize that someone recently proposed something like this in a recently released preprint (*Reinforcement Pre-Training).* This research was praised on twitter (the title sounds important, and the figure is funny!) but disappointed a lot of researchers:

Headliner figure from the recent ‘Reinforcement Pre-Training’ paper, which also proposes the idea of pretraining for RL via next-token prediction.
To be more specific, this paper proposed something similar to what I’m advocating for: using large unlabeled text datasets and next-token prediction to scale RL! And it has pretraining in the name, just like I was describing.
Alas, it turns out to be a classic case of academic titlegrabbing. What the paper actually does is very specific: they finetune a single model with chain-of-thought to improve single-token outputs for some multiple-choice questions. They’re not actually doing pretraining–just finetuning!– and train on a small subset of questions from a single math dataset. There aren’t a lot of comparisons to any of the other RLVR papers, so it’s hard to tell whether this thing even works, and if so, when and how well.
Normally I’d file this type of work away as a sort of negative result – if a simpler and more general setting worked, they surely would have tried it in this paper, right? But that’s exactly what I don’t think we should do. My overall point in this piece is that if something makes sense from first principles, we should keep working on it until we work out all the kinks.
Making good ideas work often turns out to require significantly more labor than academic researchers expect from a single project. But this is is the price of progress.
What’s next?
It’s very exciting to me that (a) RL works and (b) no one knows the right way to do it. There is so much opportunity here. One way or another, we will have much better reasoning models in a year or two; it’s just that the path is unclear. Before we can see with clarity, we have a lot to learn. If reasoning next-token prediction turns out to really be the right way to scale RL, we’re going to need to answer all these questions and many more.
Thanks to my friends Wenting Zhao, Will Brown, and Nishanth Kumar for reading this blog post early and providing helpful feedback.
It's funny, I had the exact same reaction to that cherry cake paper. What I thought it was about before I read it closely is almost exactly the same as your post.
Really interesting! This makes a lot of sense to me. It feels closer to how humans learn than pretraining (even if its still a bit different). When I’m learning a difficult thing in a textbook, I spend a lot of time thinking in between reading sentences, and I feel like the models need that too. The current RL paradigm feels more similar to skimming and then repeatedly trying the problems at the end of the chapter.