
How to train the best embedding model in the world
one PhD later, I'm giving my secrets away for free

An unexpected side effect of graduate school was that I became the best person in the world at training text embedding models. Midway through my PhD, I trained astate-of-the-art model (using a still-unbeaten method) and I had a clear plan for how to make state-of-the-art models much better.
Sadly, the method turned out to be too expensive for an academic lab. Eventually I stopped working on these models.
Since I never got around to executing my grand vision, in this article, I’m just going to give the knowledge away for free. If you are training embedding models for your job, and want to make them better, you should use this method.
(Note: this post is more on the technical side. If you’re just here for my showerthoughts about AGI, you can skip it. But if you want to learn something, read on…)
A brief aside: how I became a world expert
This isn’t an exaggeration, by the way.
Our model, CDE, worked so well because of two different techniques we developed, both of which are somewhat difficult to implement. It beat all the other embedding models of its size in every category.
How did I become the world expert on this topic? First of all, it’s not that competitive. People don’t care about embedding models that much, and most people who do are in industry. OpenAI, Anthropic, Google, and Cursor all train internal embedding models, but mostly don’t publish; when they do, they mostly just change the data.
Within academia, embedding models aren’t that popular, and there aren’t many new ideas. I think what really worked for me was having a supportive advisor who forced me to go deep. I didn’t just look at how people were training these models (boring); I spent my time understanding the fundamental underlying techniques like noise contrastive estimation and softmax approximations.
The big idea
Now that I’ve established such impressive credentials, let me explain the big idea.
It all comes back to scaling
Why haven’t we scaled embedding models?
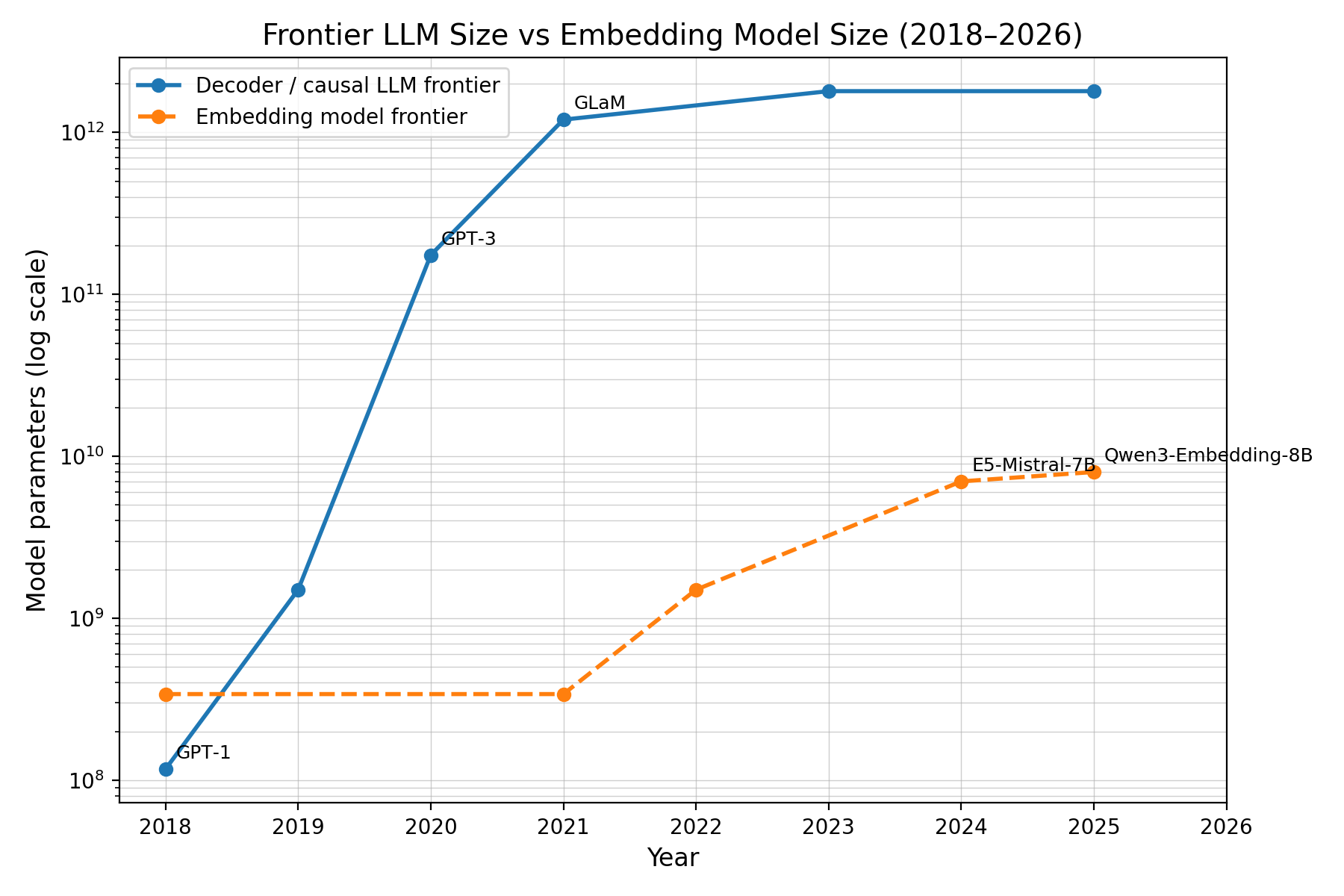
The best LLMs get bigger every year, while embedding models haven’t grown past the eight-billion parameter scale. (Thanks for the graph, chatGPT!)
Language models have seen extreme success from training longer on more data with more parameters. Embedding models haven’t seen similar returns to investment: typically we see embedding models don’t improve much from training on larger document sizes. It depends on the setting, but performance tends to plateau on training sets around 10M document-document pairs. No one is training on billions of pairs (and if it worked, they surely would be).
So why is it that don’t embedding models scale? First, let’s see a brief overview of contrastive learning, the canonical training algorithm for these models.
How embedding models work
The training objective for embedding models often looks something like this:
here, f(q) is an embedding vector, and f(q) · f(d) is the similarity between a document d and query q. The effect is to make query-document pairs close in embedding space.
Critically, this loss is applied to each batch of d’s and q’s. To train an embedding model, we sample a batch, apply this loss within the batch, and iterate.
If you go back to the basics, you’ll realize that this is essentially a form of sampled softmax, an old technique people used to use when they didn’t have enough GPU memory to compute a full softmax. It’s gone out of fashion, but what we really want is to compute scores over everything in an entire dataset:
Conventional embedding model-training optimizes the left equation. This is a Monte-Carlo approximation of the right quantity, which involves computing embedding similarities over the entire dataset.
(Note: Once, for another paper, I trained an embedding model where we *did* have perfect labels, since it was matching up two views of the same person. In this case, I optimized the exact softmax via coordinate ascent and worked much better than NCE loss.)
The data problem
Ideally we would compute the quantity on the right – for each query, we would compare its embedding to the embedding of the proper document as well as all other documents in the dataset. If this worked perfectly, we could scale ad nauseam and produce better-and-better embedding models.
The reason naive scaling doesn’t work here is that as we reduce the approximate-ness of the softmax, we introduce a lot of noise. There are many papers about this in both vision and text.
Let’s take an example query from the popular MSMarco search dataset:
was ronald reagan a democrat?
This query corresponds to multiple labeled documents from Wikipedia that answer the question. And it’s clear that most documents on the web do not answer this question.
But as you scale the number of documents, you’re likely to run into more and more “collisions” that answer this question. And that means in our exact softmax above, you’ve introduced more noise into its gradient, since some of the terms in the denominator are incorrect.
In other words: say we scale our data and accidentally include a new document that mentions Ronald Reagan’s political affiliation. This document will automatically be marked as a non-answer to the pre-existing query, and we will incorrectly encourage the model to push the embedding of the new document away from the embedding of was ronald reagan a democrat?
Over time, this type of noise compounds and scaling embedding data can actually hurt.
Incidentally, this is the exact problem tackled in many recent retrieval papers; in our CDE work, the reason why we were able to make contextual batching work at all is because we aggressively filtered these fake negatives within the batch.
In that setting, we observed nearly a 10% improvement by implementing a very crude embedding-based filtering mechanism:
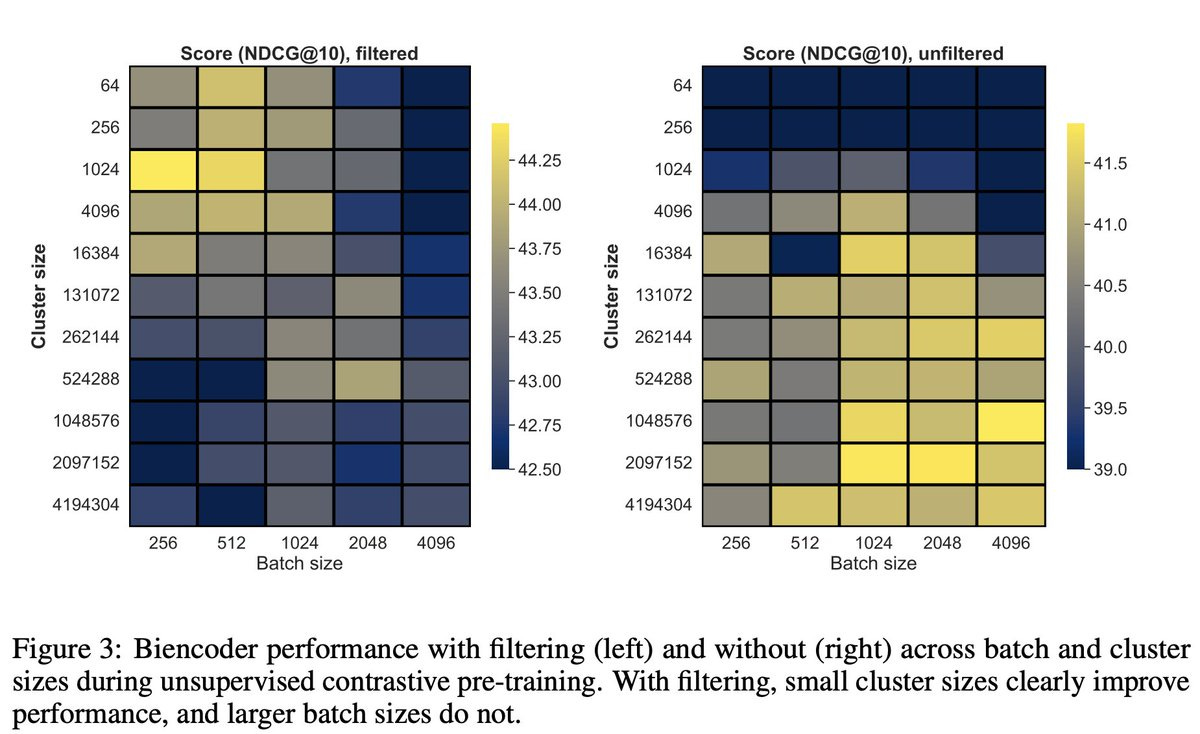
In CDE, training with filtering gave us nearly a 10% improvement (compare left graph to right graph scale).
LLMs to the rescue
The difficult realization here is that for D training query-document pairs, we technically need D^2 labels to compute the exact softmax. This is an intractable number of labels for human labeling pipeline: e.g. for a billion-pair corpus, we’d need 10^18 ≈ one quintillion human labels to deduplicate the entire corpus. (We could reduce this number with some filtering + reranking, but this relies on another retrieval model, which perhaps defeats the purpose...)
Luckily, we can exploit a property that’s become common for RL-training, known as verification asymmetry or the Generator-Verifier gap. The main idea here is the same: regular LLMs are much, much smarter than embedding models (and more expensive!). If we could train an embedding model that agrees with the decision of an LLM for every possible query-document pair, that would be an enormous accomplishment.
So let’s forget human labels. We can use LLMs to label this kind of massive dataset. This way we can end up with a nearly perfect deduplicated dataset for training embedding models. (Using LLMs on every query-document pair also opens the door for training even better models using more precise ranking algorithms...)
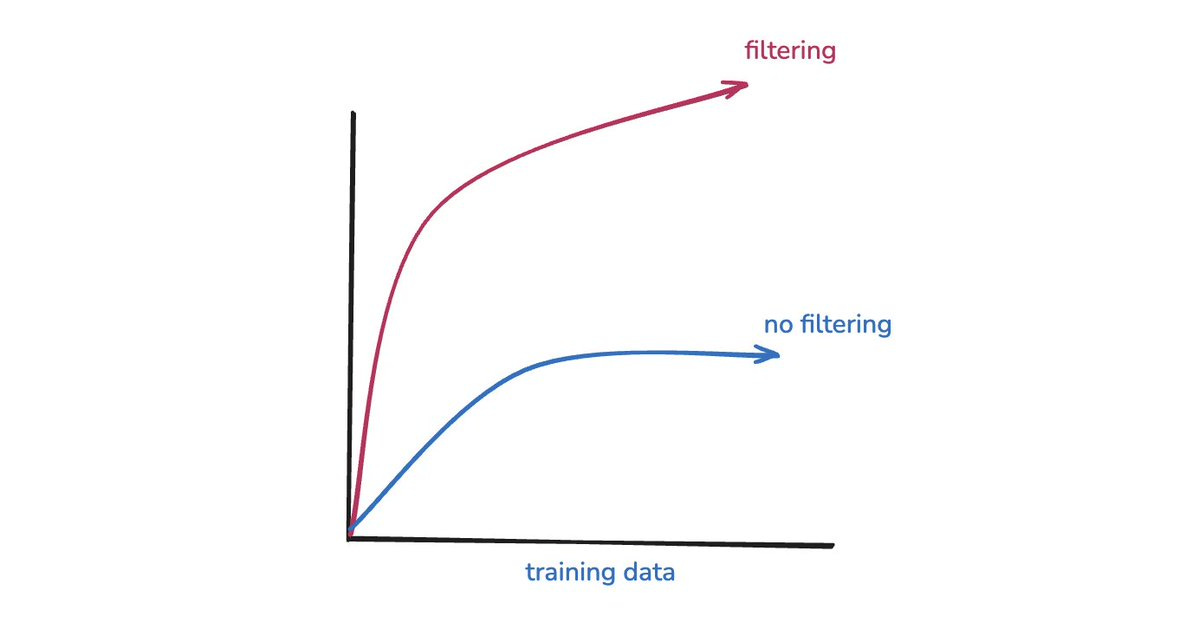
Every experiment I ran looks something like this: embedding model training scales, but only when you properly filter for hard negatives.
The full procedure
I’d be remiss if I didn’t end by explaining *exactly* how to train this model. Here’s a short recipe for training a state-of-the-art embedding model, guaranteed to beat any existing embedder:
Gather all the text pairs you can find.
is a good start. Recent work has generated large amounts of synthetic data
For each query Q, filter the top-k using BM25 and embeddings. Gain some set of K documents {D_1, ..., D_K}, relevant to Q. (This is just a practical step to make labeling tractable.)
Run each pair (D_*, Q) through an LLM to figure out if D is truly a negative example or not.
Output: a perfectly-labeled retrieval dataset that’s arbitrarily scalable.
Train the model using exact softmax and coordinate ascent.
If you have the money to run this — let me know how it goes! Happy to talk over DM or email.
What would help audience to engage more with this article is to start with why focusing on embedding model is important?
Accidently, this article has an interesting section on using Monte Carlo to approximate Softmax.