
The Case for More Ambition
why AI researchers should dream bigger and publish less

What are the most important problems in your field? And why aren’t you working on them?
This is the pitch made by Richard Hamming in his famous talk You and Your Research. It’s been nearly forty years since the talk was first given and yet it feels like more people are ignoring this advice than ever before.
This may be especially true in AI.
Our field is full of brilliant people – researchers, engineers, scientists. Students are flocking to major in computer science and learn about the technology from an early age. More people are applying to graduate school than ever before. The AI labs are raising money and publishing all sorts of findings in preprints and blog posts.
And yet it doesn’t feel like the actual science is progressing faster than it was five years ago. We’re publishing more papers than ever, but discovering about the same amount. I don’t think it’s a talent issue, and it’s certainly not a funding issue. I think we have an ambition issue.
More papers are being published than ever
This year there were over 25,000 papers submitted to NeurIPS. This represents 30% annual growth since 2017, when around 3,000 papers were submitted. This growth comes from all sorts of places. More companies are doing AI research. More universities are doing AI research. More people are getting into AI research.
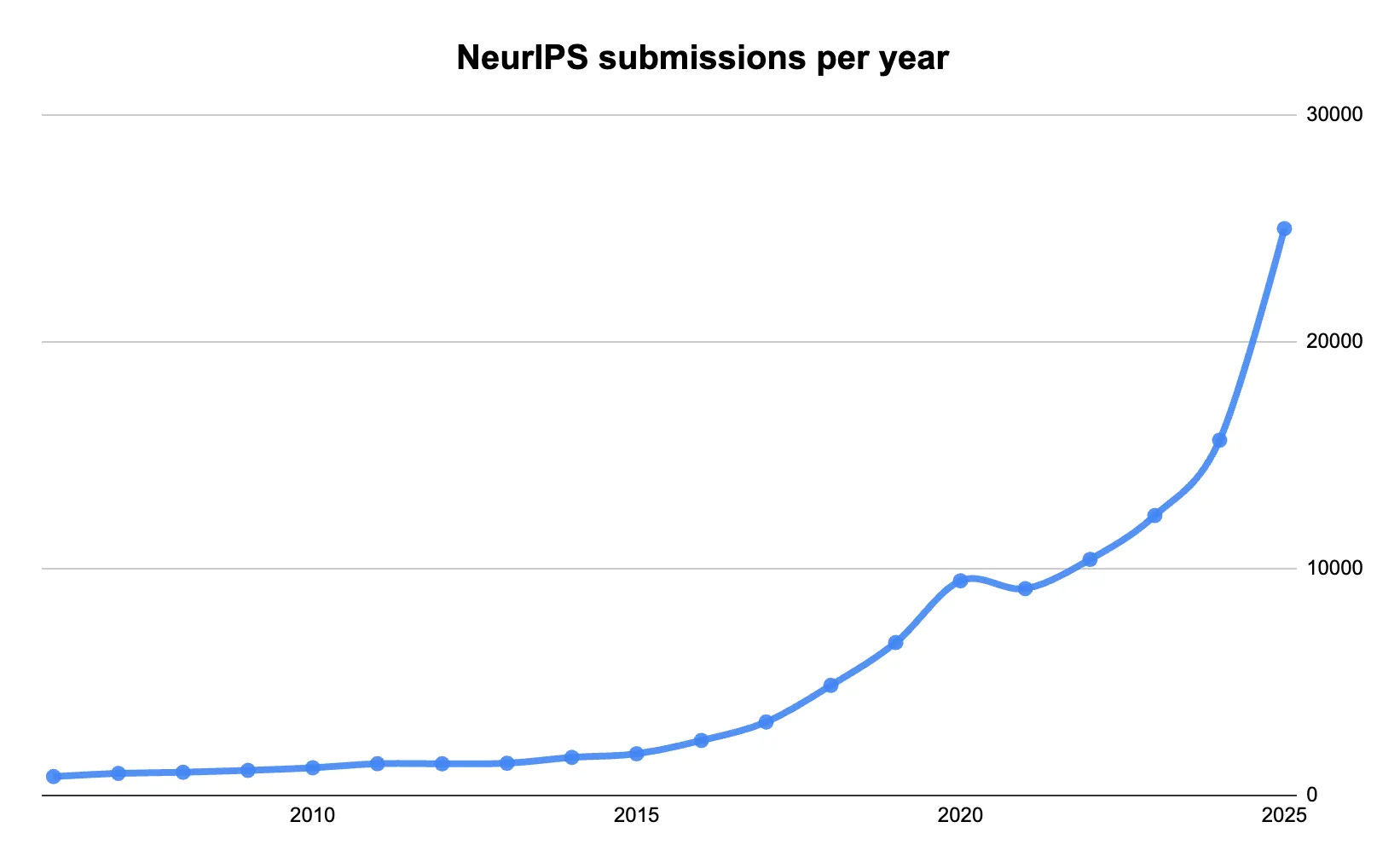
The number of submitted papers to NeurIPS, the most popular AI conference, over the last fifteen years. It’s nearing exponential growth territory. (Data from papercopilot.com)
With more people writing more papers about more different topics we’d expect some explosive growth. And yet I’d argue that the pace of progress feels pretty constant, if not slowing down by a small margin. This is a difficult thing to measure, so I polled a bunch of researchers:
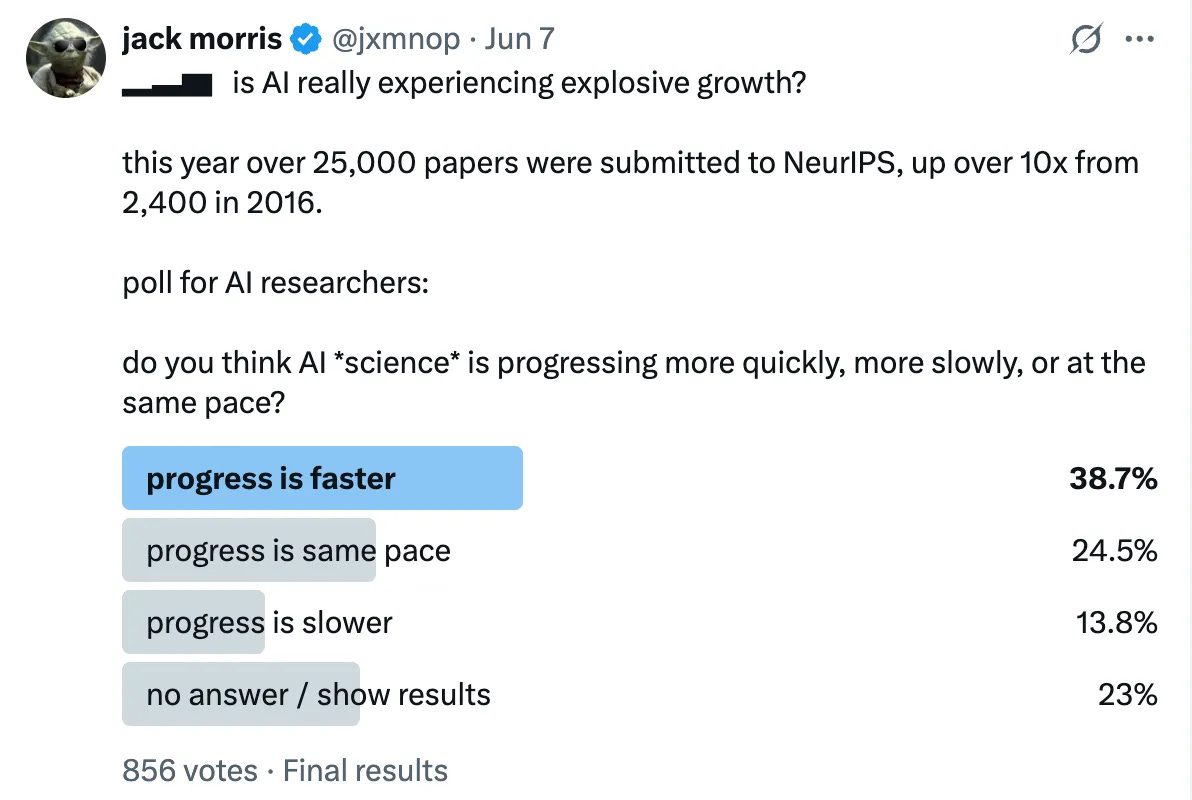
If we take the mean response here we find that progress is moving faster – but only a bit. This should be surprising in an area that’s seen explosive growth along just about every dimension.
Expanding the space of everything
If we’re publishing exponentially more, why aren’t we learning exponentially more? One possible explanation is that the space of possible ideas we’re exploring has stayed a constant size, but the number of explorers has grown at a near-exponential pace. If this is an accurate model, then the world of research looks something like this:

If the number of researchers has increased by 10x, but amount of space is only slightly larger, then the current landscape of research looks something like the bubble on the right – but at a larger scale. And maybe packed tighter.
This mental model explains why many AI researchers report experiencing anxiety and frustration around the current research and publication process. There are so many people doing so many things that it’s simply hard to find any open space to occupy.
I think this anxiety also comes from a mindset that the amount of ‘research territory’ is constant, and good research will come from interpolating between existing ideas, rather than pushing forward into the unknown. This is exactly what Hamming warns against.
And this also means that the best research expands the space of territory available to us to explore. And yet clearly most research is doing something different – most papers aren’t groundbreaking. They’re comfortably nestled somewhere in high-dimensional space, in some unoccupied pigeonhole between things that already exist.
Let’s think of research ideas in physical terms. New research can be territory-expanding, in that it opens up more space for other researchers than it consumes, or territory-consuming, in that it `eats' some of the available territory without giving anything back.
The best research is territory-expanding. It's generous. It leaves things to the imagination, sparks more ideas than it explores. It’s explorative rather than exploitative. The most important research always has this property, where it expands space more than occupies it.
So why aren’t more people doing this kind of research?
Good research takes ambition
My theory for why most research isn’t territory-expanding is because the odds of producing something groundbreaking with a project are directly proportional to its chance of failure. This means that if you set out to change the world, you will probably fail. The converse here is that if you set your sights low, and choose a topic that’s more likely to bear fruit in some way, then your chances of `success' (publishing something) are higher, but the chances of it expanding the space of knowledge are smaller.
And thus, we end up with 25,000 NeurIPS submissions. This is what happens when the community optimizes too strongly for the number of papers submitted and too loosely for solving big problems.
I also want to recognize that for some groups, external factors are at play. I’ve been told that you need to publish at least one paper to get into a CS graduate program these days – meaning there are many people who just need to publish something, even if it isn’t their best work. And some tech companies prevent employees from publish findings that feel too important, giving their workers have a perverse incentive to make their research sound small to give their work a chance to see the light of day. Let’s ignore both of these edge cases.
Higher ambition means a higher rate of failure
One question every researcher should ask: what are you optimizing for?
If your goal as a researcher is to publish as much as possible and reach the maximum h-index then logic says to lower your ambition to the minimum possible level such that you can still publish. After a bit of practice, a good researcher with the singular goal of publishing can often write papers every few months. You’ll see this happen. Some conferences even have PhD students publishing multiple papers in the same conference indicating that they worked on multiple projects at the same time (I’m not pointing any fingers, as I have also done this once. Also, it can happen for different timeline-related reasons.)
If your goal is to move the field forward then you should plan differently. Raise your level of ambition. Try crazy things.
A consequence of this is that you will publish less. Deadlines will come around for which you have nothing to show. Perhaps you found out that your idea has already been done, or doesn’t work at scale, or is doing things that you just don’t understand. The most likely explanation is that most great things take more than three months to execute.
(As an aside, I have been doing research for six years or so and have already found that periods without publishing are really just fine. People care most about the one or two projects you’ve ever worked on that are most exciting. They care much less about the six month gaps where you were quietly trying to make something work. In my own career this has already happened several times: I spent my year in the Google AI Residency working on something that never quiet worked. I worked on a music model for six months that never went anywhere. In the third year of my PhD I wanted to build a contextual embedding model, which was a neat idea but took over a year to get the details right. The list does not stop there…)
Most research doesn’t matter much in the long run
But if you look back at the conference proceedings from ten years ago, they don’t feel exceptionally relevant:

These are interesting and important problems, but have almost nothing to do with the AI systems we use today. This makes one wonder how much of the content from this year’s 25,000 NeurIPS papers might still be relevant in 2035.
You might have your own hypotheses on why academic research tends toward small-but-eventually-forgotten problems. Predicting the future is hard. And most research moves in cycles that last less than a year, so it’s important to choose problems that are tractable within that timeframe.
Research that stands the test of time
For our purposes, we’re talking about research that affects the way we think about or design modern AI systems. This is an exceptionally small sliver of research papers. Under this definition, I’d guess less than 1% of published AI research ‘matters’.
Why is this number so small? One explanation is that modern AI grew out of machine learning and probabilistic modeling, which is a much deeper subfield with many sub-areas of study that have nothing to do with modern AI. Here’s one example: if you took statistics in school, you know that modern statistics is divided into two schools (Bayesian and frequentist) but modern AI is totally frequentist. Even though lots of people have researched Bayesian neural networks, they’ve basically been abandoned in favor of learning everything from data without a prior.
So what makes up this 1%? What research matters? To answer this question, let’s first gather a bit of data. NeurIPS (the biggest AI conference) gives “Test of Time” awards to ten-year-old papers that have made an outsized impact over the preceding decade. I asked Deep Research to gather me a list of the papers that have won the award:

Out of the ten papers that have won the Test-of-Time award, I notice the following themes:
These are simpler than the average NeurIPS paper
Each of them seems to leverage more data and more compute than was common at the time
And let’s remember that basically all deep learning research changed with the ImageNet paper in 2012, which only won its test-of-time award in 2022. So only the awards from 2022–2024 reflect research from the “modern” (post-AlexNet) era.
We can clearly see that in the long run, the AI research that matters is research that (a) is simple and (b) scales well. In fact, modern AI systems like Claude 4 and Veo 3 are so simple that they use almost none of the decades of published ML research. And yet this is likely what Hamming would have predicted – in the end, most science is forgotten.
This is probably a good thing. Downstream effects are that AI is easy for newcomers to learn, and relatively simple to implement. And it seems quite reasonable to bet that the next big breakthroughs in AI will be simple.
Remind yourself that simple questions are often the most ambitious. They often also take the longest to mentally grapple with, and are the hardest to engineer experiments for.
Putting Hamming’s advice into practice
I suspect that the problem here isn’t lack of ambitious ideas, it’s more related to a fear of failure. Most people that have done research for a long time confront big, messy, unanswered questions that continually resurface through day-to-day experimentation.
It seems the best strategy is to do whatever you can to can to confront those questions directly. There is no question too big to make into a research project. Einstein famously used the thought experiment of riding along on a beam of light to explore the ideas that ended up revolutionizing modern physics. What’s your question like this?
Perhaps you want to imagine your own personal data being stored inside an LLM, or what it would be like to slide down a gradient during training, or some new mechanism for visualizing and manipulating the internals of an LLM as it processes a sequence along during inference.
Hamming also notes that the best way to move forward is often by talking to capable people that you trust. He specifically mentions that solo daily brainstorming sessions haven’t proved fruitful in his career. The best way to make progress, he says, is to talk to someone and explain where you’re starting from all the way up to the point where you get stuck.
Maybe the specific question isn’t even that important, since so few people seem to be thinking like this. The bottom line is that we’d all be better off if most people worked on big ambitious projects for a longer time. We would see fewer papers, but each individual paper would have more depth. By publishing less, we would move faster.
Thanks to Ege Erdil for Jeffrey Emanuel for feedback on an early draft of this post.
I appreciate this idea of territory-expanding research.
While I agree we should be aiming higher and for, say, deep novelty, I'm not convinced higher ambition is positively correlated with failure. The opposite seems true! I see in the screenshot that Ilya authored a winning test-of-time paper *every single year* of the modern era. Einstein published 4 absolutely seminal papers in *7 months* during his famous "miracle year" of 1905 (all of which expanded huge territory in quite different directions). This phenomenon of repeat success has also been noted in other domains[1].
1. https://blakemasters.tumblr.com/post/23435743973/peter-thiels-cs183-startup-class-13-notes
This reminds me of Fei-Fei Li's autobiography, "The Worlds I See":
"'Well, Fei-Fei…' he began, choosing his words carefully. 'Everyone agrees that data has a role to play, of course, but…' He paused for a moment, then continued. 'Frankly, I think you’ve taken this idea way too far.' I took a shallow breath. 'The trick to science is to grow with your field. Not to leap so far ahead of it.'... A frightening idea was beginning to sink in: that I’d taken a bigger risk than I realized, and it was too late to turn back."